前言
1985年Ken Perlin指出,一个理想的噪声应该具有以下性质:维基百科
1.对旋转具有统计不变性;
2.能量在频谱上集中于一个窄带,即:图像是连续的,高频分量受限;
3。对变换具有统计不变性。
本文目的是以一种通俗简单的方式介绍Ken Perlin的改进版柏林噪声算法,讲解代码采用c#编写。
Perlin noise简介
柏林噪声是一个非常强大算法,经常用于程序生成随机内容,在游戏和其他像电影等多媒体领域广泛应用。算法发明者Ken Perlin也因此算法获得奥斯卡科技成果奖。在游戏开发领域,柏林噪声可以用于生成波形,起伏不平的材质或者纹理。例如,它能用于程序生成地形(例如使用柏林噪声来生成我的世界(Minecraft)里的地形),火焰燃烧特效,水和云等等。柏林噪声绝大部分应用在2维,3维层面上,但某种意义上也能拓展到4维。柏林噪声在1维层面上可用于卷轴地形、模拟手绘线条等。 如果将柏林噪声拓展到4维层面,以第4维,即w轴代表时间,就能利用柏林噪声做动画。例如,2D柏林噪声可以通过插值生成地形,而3D柏林噪声则可以模拟海平面上起伏的波浪。下面是柏林噪声在不同维度的图像以及在游戏中的应用场景。
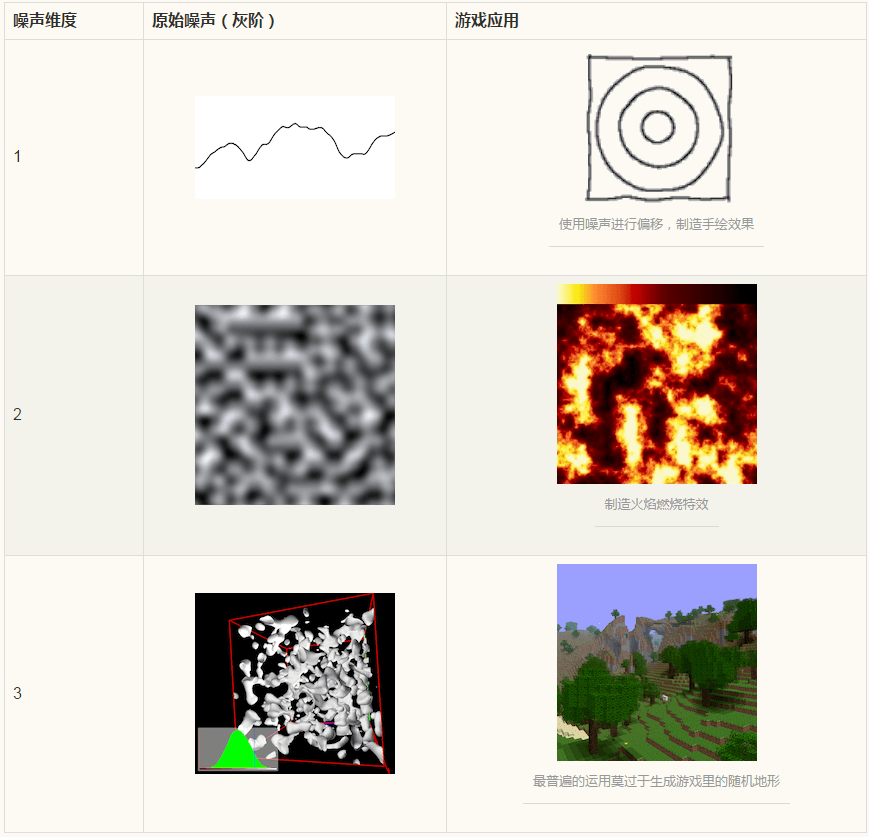
Perlin noise 关键词
伪随机是指,对于任意组相同的输入,必定得到相同的输出。 举个例子来理解伪随机,比如我们从圆周率π(3.14159…)的小数部分中随机抽取某一位数字,结果看似随机,但如果抽取小数点后1位,结果必定为1;抽取小数点后2位,结果必定为4。
梯度向量代表该顶点相对单元正方形内某点的影响是正向还是反向的(向量指向方向为正向,相反方向为反向)。 在本文所介绍的改进版柏林噪声中,这些梯度向量并不是完全随机的,而是由12条单位正方体(3维)的中心点到各条边中点的向量组成:
(1,1,0),(-1,1,0),(1,-1,0),(-1,-1,0), (1,0,1),(-1,0,1),(1,0,-1),(-1,0,-1), (0,1,1),(0,-1,1),(0,1,-1),(0,-1,-1)Ken Perlin’s SIGGRAPH 2002 paper: Improving Noise这篇文章中描述了选用这些特定梯度向量背后的推理.
基本原理
我们先从最基本的柏林噪声函数看起:
public float perlin(float x, float y, float z);
输入一个坐标的x,y,z,我们得到一个介于0.0和1.0之间的float值。那么我们怎么处理输入的坐标值?首先,我们将x,y和z坐标分成单位立方体。换句话说,找到[x,y,z] % 1.0立方体内坐标的位置(取输入坐标值x,y,z的小数点部分)。下面是这个概念的二维表示:
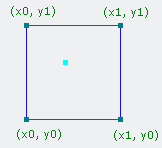
图1:小蓝点代表输入值在单元正方形里的空间坐标,其他4个点则是单元正方形的各顶点
接着,我们给4个顶点(在3维空间则是8个顶点)各自生成一个伪随机的梯度向量。梯度向量代表该顶点相对单元正方形内某点的影响是正向还是反向的(向量指向方向为正向,相反方向为反向)。而伪随机是指,对于任意组相同的输入,必定得到相同的输出。因此,虽然每个顶点生成的梯度向量看似随机,实际上并不是。这也保证了在梯度向量在生成函数不变的情况下,每个坐标的梯度向量都是确定不变的。
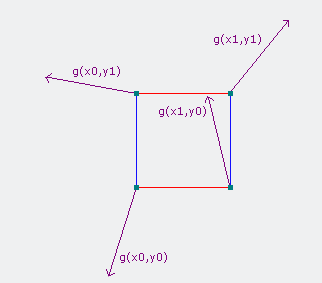
图2:各顶点上的梯度向量随机选取结果
注意,上图所示的梯度向量并不是绝对的。在本文所介绍的改进版柏林噪声中,这些梯度向量并不是完全随机的,而是由12条单位正方体(3维)的中心点到各条边中点的向量组成:
(1,1,0),(-1,1,0),(1,-1,0),(-1,-1,0),
(1,0,1),(-1,0,1),(1,0,-1),(-1,0,-1),
(0,1,1),(0,-1,1),(0,1,-1),(0,-1,-1)
Ken Perlin’s SIGGRAPH 2002 paper: Improving Noise这篇文章中描述了选用这些特定梯度向量背后的推理.
接下来,我们需要计算从给定点到网格上8个周围点的4个向量(3D中的8个向量)。下面显示了2D中的一个示例。
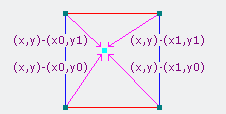
图3:示例距离矢量
接下来,我们取两个向量之间的点积(梯度向量和距离向量)。我们就可以得出每个顶点的影响值:
dot(grad,dist) = grad.x * dist.x + grad.y * dist.y + grad.z * dist.z
这正是所需要的,因为2个向量的点积等于两个向量之间夹角的余弦乘以那些向量的大小:
dot(vec1,vec2) = cos(angle(vec1,vec2)) * vec1.length * vec2.length
换句话说,如果2个向量指向相同的方向,则点积将等于:
1 * vec1.length * vec2.length
如果两个向量指向相反的方向,则点积将等于:
-1 * vec1.length * vec2.length
如果两个向量垂直,则点积为0。
因此,点积的结果在梯度方向上为正,在相反时为负。这就是梯度矢量如何决定正方向和负方向。下面通过一副彩色图,直观地看下各顶点的影响值:
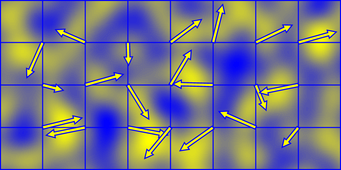
图4:这些影响在二维噪声中的表示。
现在我们需要做的就是在这四个值之间进行插值,这样我们就可以在4个网格点之间得到一种加权平均值(3D中的8个点)。解决这个问题很简单:像这样取得平均值(这个例子是2D的):
// 以下是假设的4个影响值:
// [g1] | [g2]
// -----------
// [g3] | [g4]
int g1, g2, g3, g4;
//这两个坐标是输入坐标在其单位平方中的位置。
//例如,(0.5,0.5)位于其单位平方的中心。
int u, v;
int x1 = lerp(g1,g2,u);
int x2 = lerp(g3,h4,u);
int average = lerp(x1,x2,v);
还有一个最后问题:使用上述加权平均值,最终结果看起来很糟糕,因为线性插值虽然计算便宜,但看起来不自然。我们需要渐变之间的平滑过渡。所以,我们使用淡入淡出功能,也称为缓动曲线(fade函数,通常也被称为ease curve,在游戏中广泛使用):
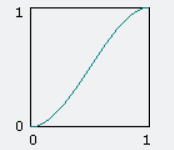
图5:缓动曲线
这个缓动曲线适用于上述代码示例中的u和v值。随着接近目的坐标,变化会更加渐进(也就是在当数值趋近于整数时,变化变慢)。改进的Perlin噪声实现的淡入淡出功能的fade函数可以表示为以下数学形式:
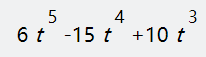
逻辑上就是这样!我们现在搞清了算法实现的各个关键步骤后。现在让我们编写一些代码。
应用与代码
准备工作
第一步,我们需要先声明一个排列表(permutation table),perm[]数组。数组长度应为256,分别随机、无重复地存放了0-255这些数值。为了使计算梯度时更加效率,在数组末尾增加一个数组首位的值151。所以perm[]数组长度为257。
private static readonly int[] perm = {
151,160,137,91,90,15,
131,13,201,95,96,53,194,233,7,225,140,36,103,30,69,142,8,99,37,240,21,10,23,
190, 6,148,247,120,234,75,0,26,197,62,94,252,219,203,117,35,11,32,57,177,33,
88,237,149,56,87,174,20,125,136,171,168, 68,175,74,165,71,134,139,48,27,166,
77,146,158,231,83,111,229,122,60,211,133,230,220,105,92,41,55,46,245,40,244,
102,143,54, 65,25,63,161, 1,216,80,73,209,76,132,187,208, 89,18,169,200,196,
135,130,116,188,159,86,164,100,109,198,173,186, 3,64,52,217,226,250,124,123,
5,202,38,147,118,126,255,82,85,212,207,206,59,227,47,16,58,17,182,189,28,42,
223,183,170,213,119,248,152, 2,44,154,163, 70,221,153,101,155,167, 43,172,9,
129,22,39,253, 19,98,108,110,79,113,224,232,178,185, 112,104,218,246,97,228,
251,34,242,193,238,210,144,12,191,179,162,241, 81,51,145,235,249,14,239,107,
49,192,214, 31,181,199,106,157,184, 84,204,176,115,121,50,45,127, 4,150,254,
138,236,205,93,222,114,67,29,24,72,243,141,128,195,78,66,215,61,156,180,
151
};
perm[]数组会在后续的哈希计算中使用到,用于确定一组输入最终决定哪个梯度向量(从前面所列出的12个梯度向量中挑选)。后续代码会详细展示perm[]数组的用法。
接着,我们开始编写柏林噪声方法:
public static float Noise(float x, float y, float z)
{
//计算输入点所在的“单位立方体”。0xff = 255
var X = Mathf.FloorToInt(x) & 0xff;
var Y = Mathf.FloorToInt(y) & 0xff;
var Z = Mathf.FloorToInt(z) & 0xff;
//左边界为(|x|,|y|,|z|),右边界为 +1。接下来,我们计算出该点在立方体中的位置(0.0~1.0)。
x -= Mathf.Floor(x);
y -= Mathf.Floor(y);
z -= Mathf.Floor(z);
//...
}
这段代码很好解释。首先,我们创建变量X,Y,Z;它们代表了输入坐标落在了哪个单位立方体里。我们还要限制坐标在[0,255]这个范围内,这样我们在访问perm[]数组时就不会遇到溢出错误。这也产生了一个不好的副作用:佩林噪音总是重复每256个坐标。这不是太大的问题,因为坐标的小数点能够影响这个结果。最后我们在单位立方体内找到我们的坐标位置。这实质上为 n = n % 1.0 ,则 n 是坐标的位置。
Fade函数
现在我们需要用代码表示前面所提到的fade函数(图5)。正如上文所提,函数的数学表示:
代码:
static float Fade(float t)
{
return t * t * t * (t * (t * 6 - 15) + 10);
}
public static float Noise(float x, float y, float z)
{
//...
var u = Fade(x);
var v = Fade(y);
var w = Fade(z);
//...
}
计算得出的 u / v / w 变量将在后面的插值计算中使用到。
哈希函数
柏林噪声哈希函数用于获取每个坐标输入的唯一值。根据维基百科定义的哈希函数是:
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。输入数据中的细微差异会在输出数据中产生非常大的差异。
这是Perlin Noise使用的散列算法。它使用我们之前创建的perm[]数组:
public static float Noise(float x, float y, float z)
{
//...
var A = (perm[X] + Y) & 0xff;
var B = (perm[X + 1] + Y) & 0xff;
var AA = (perm[A] + Z) & 0xff;
var BA = (perm[B] + Z) & 0xff;
var AB = (perm[A + 1] + Z) & 0xff;
var BB = (perm[B + 1] + Z) & 0xff;
var AAA = perm[AA];
var BAA = perm[BA];
var ABA = perm[AB];
var BBA = perm[BB];
var AAB = perm[AA + 1];
var BAB = perm[BA + 1];
var ABB = perm[AB + 1];
var BBB = perm[BB + 1];
//...
}
梯度函数
Ken Perlin的最初版算法里的grad()函数写法过于复杂,令人费解。我们只要明白grad()函数的作用在于计算随机选取的梯度向量以及顶点位置向量的点积。Ken Perlin巧妙地使用了位翻转(bit-flipping)技巧来实现:
static float grad(int hash, float x, float y, float z)
{
//取散列值,取其前4位(15 = 0b1111)
var h = hash & 15;
//如果哈希的最高有效位(MSB)为0,则设置 u=x,否则为y。
var u = h < 8/* 0b1000 */ ? x : y;
//如果第一与第二有效位为0,则 v=y
//如果第一或第二有效位是1,则 v=x
//如果第一和第二有效位不等于(0/1,1/0)则v=z
var v = h < 4/* 0b0100 */ ? y : (h == 12 /* 0b1100 */ || h == 14/* 0b1110*/ ? x : z);
//使用最后2位来判断u和v是正还是负,然后返回它们的和。
return ((h & 1) == 0 ? u : -u) + ((h & 2) == 0 ? v : -v);
}
以下是以更易于理解的方式实现上述代码功能的另一种方式(实际上在许多语言中速度更快):
// Source: http://riven8192.blogspot.com/2010/08/calculate-perlinnoise-twice-as-fast.html
public static float Grad(int hash, float x, float y, float z)
{
switch(hash & 0xF)
{
case 0x0: return x + y;
case 0x1: return -x + y;
case 0x2: return x - y;
case 0x3: return -x - y;
case 0x4: return x + z;
case 0x5: return -x + z;
case 0x6: return x - z;
case 0x7: return -x - z;
case 0x8: return y + z;
case 0x9: return -y + z;
case 0xA: return y - z;
case 0xB: return -y - z;
case 0xC: return y + x;
case 0xD: return -y + z;
case 0xE: return y - x;
case 0xF: return -y - z;
default: return 0; // never happens
}
}
上面代码的来源可以在这里找到。两个版本的结果都是一样的。他们从以下12个向量中选择一个随机向量:
(1,1,0),(-1,1,0),(1,-1,0),(-1,-1,0),
(1,0,1),(-1,0,1),(1,0,-1),(-1,0,-1),
(0,1,1),(0,-1,1),(0,1,-1),(0,-1,-1)
Grad()的第一个参数为前一步散列算法得出的哈希值,其他3个参数则代表由输入点的位置矢量(将用于与梯度向量进行点积)。
插值整合
经过前面的几步计算,我们得出了8个顶点的影响值,并将它们进行平滑插值,得出了最终结果:
public static float Noise(float x, float y, float z)
{
//...
//梯度函数计算伪随机梯度向量和输入坐标到其单位立方体中的8个顶点向量之间的点积。
//然后,基于我们先前通过Fade函数计算得到的(u,v,w)值,将这些全部进行插值计算。
float x1, x2, y1, y2;
x1 = Lerp(Grad(AAA, x, y, z), Grad(BAA, x - 1, y, z), u);
x2 = Lerp(Grad(ABA, x, y - 1, z), Grad(BBA, x - 1, y - 1, z), u);
y1 = Lerp(x1, x2, v);
x1 = Lerp(Grad(AAB, x, y, z - 1), Grad(BAB, x - 1, y, z - 1), u);
x2 = Lerp(Grad(ABB, x, y - 1, z - 1), Grad(BBB, x - 1, y - 1, z - 1), u);
y2 = Lerp(x1, x2, v);
//为了方便起见,我们将结果范围设为0~1(理论上之前的min/max是[-1,1])。
return (Lerp(y1, y2, w) + 1) / 2;
//...
}
static float Lerp(float a, float b, float t)
{
return a + t * (b - a);
}
使用Octaves
我讨论的最后一件事是如何处理Perlin噪音使结果看起来更自然。尽管柏林噪音确实提供了一定程度的自然行为,但它并不能充分表达人们在自然界可能期望的不规律性。例如,现实地形会有大段连绵、高耸的山地,也会有丘陵和蚀坑,更小点的有大块岩石,甚至更小的鹅卵石块,这都属于地形的一部分。解决这个问题很简单:你可以通过改变频率(frequencies)和振幅(amplitudes)获取多个噪声函数,并将它们相加。当然,频率是指数据采样的周期,幅度是指结果的范围。
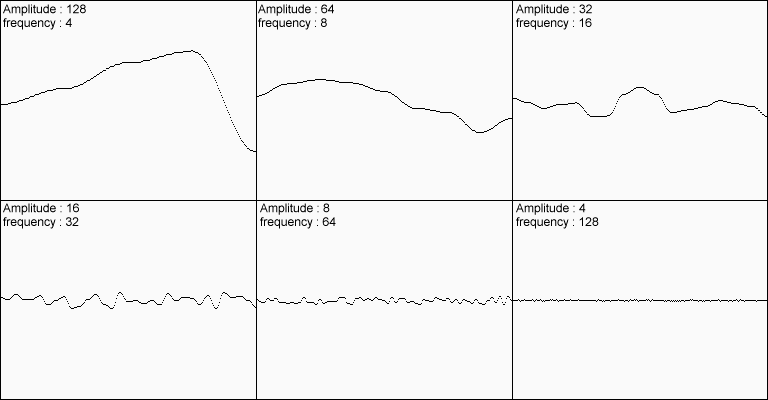
图6:6具有不同频率和幅度的示例噪声结果。
将所有这些结果加在一起,就可以得到这个结果:
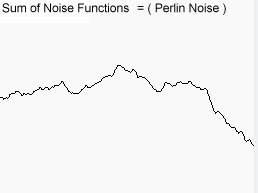
图7:图6所有噪声的叠加结果
显然这个结果更棒(๑•̀ㅂ•́)و✧。上述6组噪声被称为不同的倍频(Octave)噪声。随着倍频增大,噪声对最终结果的影响越小。当然,倍频组数的增加,代码执行时间会线性增加,所以你应该尽量不要在运行时使用更多的倍频(例如,以60fps运行的火焰特效)。但是,对数据进行预处理(如生成地形)时,使用多组倍频叠加的效果很棒。
那我们应该分别挑选多大的频率和振幅来进行噪声计算呢?这个可以通过persistence参数确定。Hugo Elias对persistence的定义使用如下:
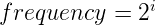
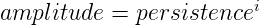
以上公式i的值取决于倍频数量,代码实现也很简单:
public static float Fbm(float x, float y, float z, int octave, float persistence = 0.5f)
{
float total = 0.0f;
float frequency = 1;
float amplitude = 1;
//用于将结果归一化
float maxValue = 0;
for (int i = 0; i < octave; i++)
{
total += amplitude * Noise(x * frequency, y * frequency, z * frequency);
maxValue += amplitude;
frequency *= 2;
amplitude *= persistence;
}
return total / maxValue;
}